
By T. Mertzimekis
What is Classification?
Classification in Machine Learning is the process of predicting the class of given data points. Classes are sometimes called as targets/labels or categories. Classification predictive modeling is the task of approximating a mapping function (f) from input variables (x) to discrete output variables (y).
For example, classification models can predict whether or not an online customer will buy a product. The output can be yes or no: buy / no buy. This binary problem is however only one limited case of how classification can be applied. Classification methods can deal with more complex problems. For example, a classification method could assess whether a given image found over the internet contains a bike or a truck. In this example, the output will be three different values: 1) the image contains a bike 2) the image contains a truck, or 3) the image contains neither a bike nor a truck.

Classification belongs to the category of supervised learning where the targets are also provided with the input data. There are many applications in classification in many domains such as in medical diagnosis, target marketing, credit approval etc.
There are two types of learners in classification: lazy learners and eager learners, briefly discussed below
Lazy learners
Lazy learners store the training data and wait until test data appear. When test data become available, classification is carried out based on the most related data in the stored training data. Compared to eager learners, lazy learners have less training time, but more time in predicting.
Examples of lazy learners are the methods of the k-nearest neighbor and the Case-based reasoning
Eager learners
Eager learners form a classification model based on the given training data before receiving any data for classification. It must be able to commit to a single hypothesis that covers the entire instance space. Due to the model formulation, eager learners take a rather long time for training, but much less time to predict.
Examples of eager learners are the methods of the Decision Tree, Naive Bayes, and the Artificial Neural Networks
Classification algorithms
Several classification algorithms exist. However, it is impossible to conclude which one is superior with respect to others. The choice of a classification algorithm depends on the application and nature of the available data sets. For example, if the classes are linearly separable, the linear classifiers like Logistic regression, Fisher’s linear discriminant can outperform sophisticated models and vice versa.
The simplest classification algorithm is logistic regression — which makes it sounds like a regression method, but it is actually not. Logistic regression estimates the probability of an occurrence of an event based on one or more inputs.
For example, logistic regression can use as inputs two exam scores for a student to estimate the probability that the student will get admitted to a particular university. Since the estimate is a probability, the output is a number between 0 and 100%, where 100% represents full certainty. For the student, if the estimated probability is greater than 50%, then we predict that s/he will be admitted. If the estimated probability is less than 50%, we predict the s/he will be refused.
Because logistic regression is the simplest classification model, it is a good place to start for classification. As we progress, non-linear classifiers such as decision trees, random forests, support vector machines, and neural nets can be more sophisticated choices for classification. Below I am briefly describing the Decision Tree model.
Decision Tree
Decision tree builds classification or regression models in the form of a tree structure. It utilizes an if-then rule set which is mutually exclusive and exhaustive for classification. The rules are learned sequentially using the training data one at a time. Each time a rule is learned, the tuples covered by the rules are removed. This process is continued on the training set until meeting a termination condition.
The tree is constructed in a top-down recursive divide-and-conquer manner. All the attributes should be categorical. Otherwise, they should be discretized in advance. Attributes in the top of the tree have more impact towards in the classification and they are identified using the information gain concept.
A decision tree can be easily over-fitted generating too many branches and may reflect anomalies due to noise or outliers. An over-fitted model has a very poor performance on the unseen data even though it gives an impressive performance on training data. This can be avoided by pre-pruning which halts tree construction early or post-pruning which removes branches from the fully grown tree.
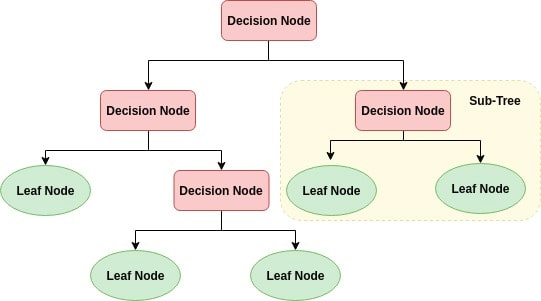
Decision Tree classifiers are very popular for a number of reasons:
- Comprehensibility: the representation of decision trees is in a form that are intuitive to the average person and therefore require little explanation. Just by looking at the diagram one is able to follow the flow of information.
- Efficiency: the learning and classification steps of decision tree induction are simple and fast
- Extendibility: decision trees can handle high dimensional data and are easy to expand based on the data set and being that their classifiers do not require any domain knowledge they can be used for exploratory knowledge discovery.
- Flexibility: decision trees are used in various areas of classification including the manufacturing and production, financially analysis, molecular biology, astronomy and medical fields.
- Portability: decision trees can be combined with other decision techniques; they currently serve as the basis of several commercial rule induction systems.
More information on Decision Trees can be found here
